library(plyr)1 aaply/ adply/ alply
Split array, apply function, and return results in an array/data frame/list
dim(ozone)## [1] 24 24 72aaply(ozone, 1, mean)## -21.2 -18.7 -16.2 -13.7 -11.2 -8.7 -6.2 -3.7
## 266.8194 263.0104 260.6493 258.8148 257.8657 256.9306 256.1007 255.6238
## -1.2 1.3 3.8 6.3 8.7 11.2 13.7 16.2
## 255.5081 255.0718 254.1771 254.5139 256.0729 258.8160 261.3009 263.7072
## 18.7 21.2 23.7 26.2 28.7 31.2 33.7 36.2
## 266.4005 269.9294 273.9062 279.5926 285.3356 293.2234 300.2546 308.7153aaply(ozone, 1, mean, .drop = FALSE)##
## lat 1
## -21.2 266.8194
## -18.7 263.0104
## -16.2 260.6493
## -13.7 258.8148
## -11.2 257.8657
## -8.7 256.9306
## -6.2 256.1007
## -3.7 255.6238
## -1.2 255.5081
## 1.3 255.0718
## 3.8 254.1771
## 6.3 254.5139
## 8.7 256.0729
## 11.2 258.8160
## 13.7 261.3009
## 16.2 263.7072
## 18.7 266.4005
## 21.2 269.9294
## 23.7 273.9062
## 26.2 279.5926
## 28.7 285.3356
## 31.2 293.2234
## 33.7 300.2546
## 36.2 308.7153aaply(ozone, 1, each(min, max))##
## lat min max
## -21.2 242 312
## -18.7 240 288
## -16.2 240 282
## -13.7 238 280
## -11.2 238 280
## -8.7 240 278
## -6.2 236 278
## -3.7 234 280
## -1.2 232 280
## 1.3 232 278
## 3.8 234 282
## 6.3 234 286
## 8.7 236 282
## 11.2 236 284
## 13.7 238 286
## 16.2 240 292
## 18.7 244 294
## 21.2 242 302
## 23.7 250 308
## 26.2 256 322
## 28.7 250 330
## 31.2 264 350
## 33.7 266 360
## 36.2 268 390adply(ozone, 1, mean)## lat V1
## 1 -21.2 266.8194
## 2 -18.7 263.0104
## 3 -16.2 260.6493
## 4 -13.7 258.8148
## 5 -11.2 257.8657
## 6 -8.7 256.9306
## 7 -6.2 256.1007
## 8 -3.7 255.6238
## 9 -1.2 255.5081
## 10 1.3 255.0718
## 11 3.8 254.1771
## 12 6.3 254.5139
## 13 8.7 256.0729
## 14 11.2 258.8160
## 15 13.7 261.3009
## 16 16.2 263.7072
## 17 18.7 266.4005
## 18 21.2 269.9294
## 19 23.7 273.9062
## 20 26.2 279.5926
## 21 28.7 285.3356
## 22 31.2 293.2234
## 23 33.7 300.2546
## 24 36.2 308.7153alply(ozone, 1, quantile)## $`1`
## 0% 25% 50% 75% 100%
## 242 258 266 278 312
##
## $`2`
## 0% 25% 50% 75% 100%
## 240 256 262 272 288
##
## $`3`
## 0% 25% 50% 75% 100%
## 240 254 260 268 282
##
## $`4`
## 0% 25% 50% 75% 100%
## 238 252 258 266 280
##
## $`5`
## 0% 25% 50% 75% 100%
## 238 252 258 264 280
##
## $`6`
## 0% 25% 50% 75% 100%
## 240 250 256 264 278
##
## $`7`
## 0% 25% 50% 75% 100%
## 236 248 254 264 278
##
## $`8`
## 0% 25% 50% 75% 100%
## 234 248 254 264 280
##
## $`9`
## 0% 25% 50% 75% 100%
## 232 248 254 262 280
##
## $`10`
## 0% 25% 50% 75% 100%
## 232 248 254 262 278
##
## $`11`
## 0% 25% 50% 75% 100%
## 234 248 252 260 282
##
## $`12`
## 0% 25% 50% 75% 100%
## 234 248 254 260 286
##
## $`13`
## 0% 25% 50% 75% 100%
## 236 250 255 262 282
##
## $`14`
## 0% 25% 50% 75% 100%
## 236 252 258 266 284
##
## $`15`
## 0% 25% 50% 75% 100%
## 238 254 260 268 286
##
## $`16`
## 0% 25% 50% 75% 100%
## 240 256 264 272 292
##
## $`17`
## 0% 25% 50% 75% 100%
## 244 258 266 274 294
##
## $`18`
## 0% 25% 50% 75% 100%
## 242 260 270 278 302
##
## $`19`
## 0% 25% 50% 75% 100%
## 250 264 274 282 308
##
## $`20`
## 0% 25% 50% 75% 100%
## 256 270 278 290 322
##
## $`21`
## 0% 25% 50% 75% 100%
## 250 274 284 294 330
##
## $`22`
## 0% 25% 50% 75% 100%
## 264 282 290 304 350
##
## $`23`
## 0% 25% 50% 75% 100%
## 266 286 296 314 360
##
## $`24`
## 0% 25% 50% 75% 100%
## 268 292 304 324 390
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
## lat
## 1 -21.2
## 2 -18.7
## 3 -16.2
## 4 -13.7
## 5 -11.2
## 6 -8.7
## 7 -6.2
## 8 -3.7
## 9 -1.2
## 10 1.3
## 11 3.8
## 12 6.3
## 13 8.7
## 14 11.2
## 15 13.7
## 16 16.2
## 17 18.7
## 18 21.2
## 19 23.7
## 20 26.2
## 21 28.7
## 22 31.2
## 23 33.7
## 24 36.22 daply/ ddply/ dlply
Split data frame, apply function, and return results in an array/ data.frame/ list
daply(mtcars, .(cyl), nrow)## 4 6 8
## 11 7 14daply(mtcars, .(cyl), colwise(mean))##
## cyl mpg disp hp drat wt qsec vs
## 4 26.66364 105.1364 82.63636 4.070909 2.285727 19.13727 0.9090909
## 6 19.74286 183.3143 122.2857 3.585714 3.117143 17.97714 0.5714286
## 8 15.1 353.1 209.2143 3.229286 3.999214 16.77214 0
##
## cyl am gear carb
## 4 0.7272727 4.090909 1.545455
## 6 0.4285714 3.857143 3.428571
## 8 0.1428571 3.285714 3.5daply(mtcars, .(cyl), function(df) colwise(mean)(df[,c(1,3,4,6)]))##
## cyl mpg disp hp wt
## 4 26.66364 105.1364 82.63636 2.285727
## 6 19.74286 183.3143 122.2857 3.117143
## 8 15.1 353.1 209.2143 3.999214ddply(mtcars, .(cyl),colwise(mean))## cyl mpg disp hp drat wt qsec vs
## 1 4 26.66364 105.1364 82.63636 4.070909 2.285727 19.13727 0.9090909
## 2 6 19.74286 183.3143 122.28571 3.585714 3.117143 17.97714 0.5714286
## 3 8 15.10000 353.1000 209.21429 3.229286 3.999214 16.77214 0.0000000
## am gear carb
## 1 0.7272727 4.090909 1.545455
## 2 0.4285714 3.857143 3.428571
## 3 0.1428571 3.285714 3.500000linmod <- function(df) {
lm(rbi ~ year, data = mutate(df, year = year - min(year)))
}
models <- dlply(baseball, .(id), linmod)
models[[1]]##
## Call:
## lm(formula = rbi ~ year, data = mutate(df, year = year - min(year)))
##
## Coefficients:
## (Intercept) year
## 118.924 -1.732coef <- ldply(models, coef)
with(coef, plot(`(Intercept)`, year))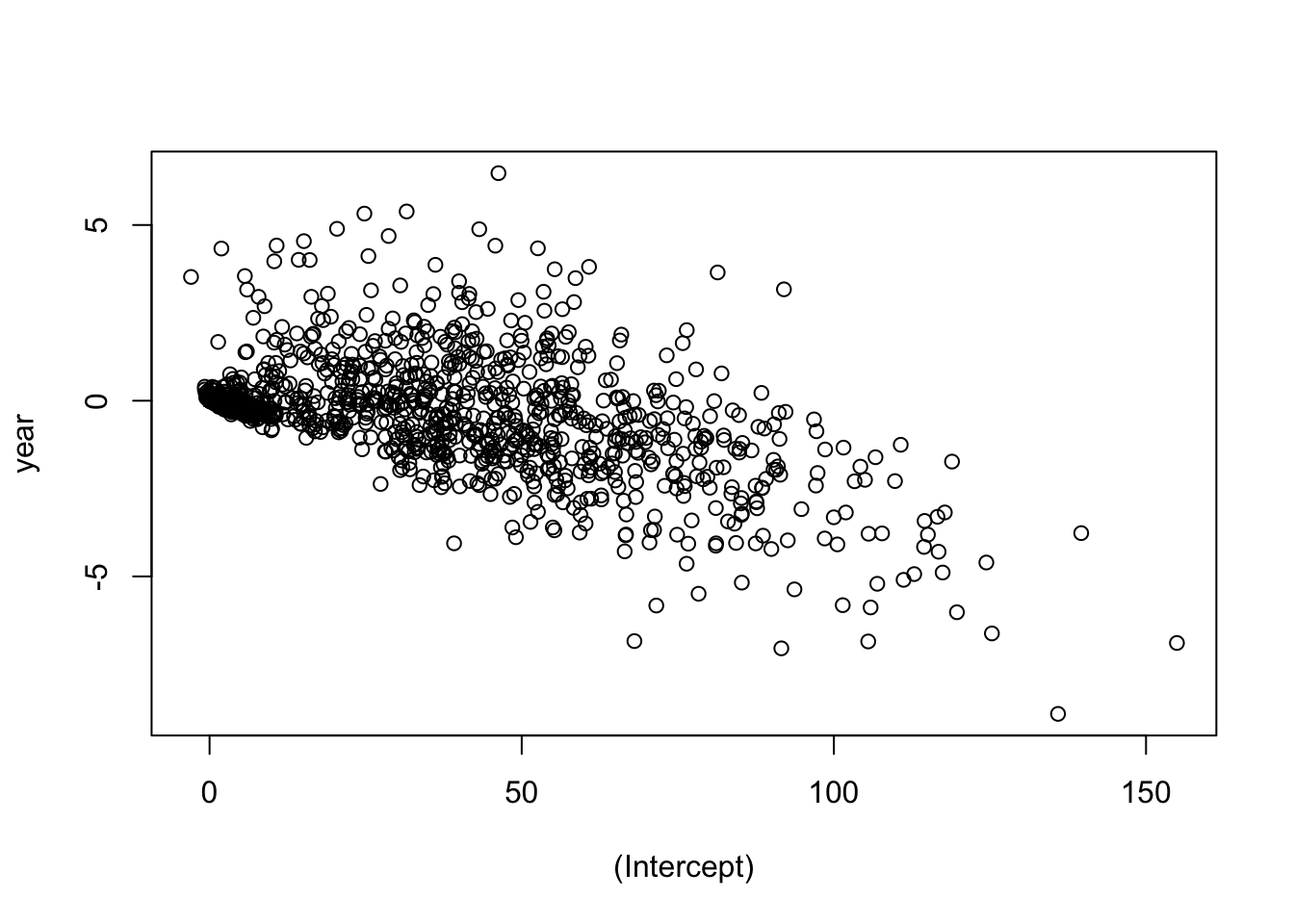
qual <- laply(models, function(mod) summary(mod)$r.squared)
hist(qual)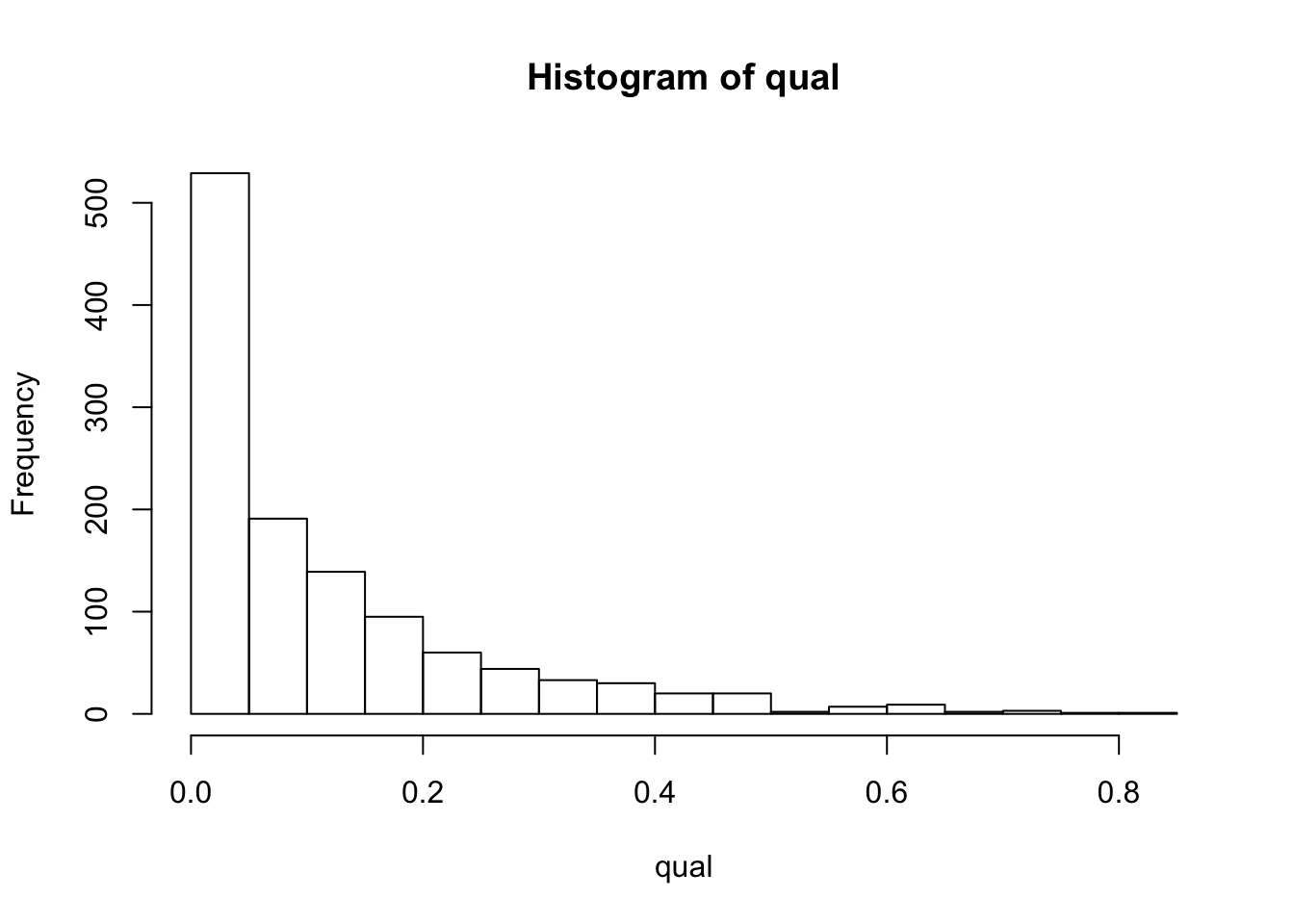
3 strip_splits
Remove splitting variables from a data frame.
dlply(mtcars, c("vs", "am"))$'0.1'## mpg cyl disp hp drat wt qsec vs am gear carb
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## 4 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## 5 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## 6 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8dlply(mtcars, c("vs", "am"), strip_splits)$'0.1'## mpg cyl disp hp drat wt qsec gear carb
## 1 21.0 6 160.0 110 3.90 2.620 16.46 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 4 4
## 3 26.0 4 120.3 91 4.43 2.140 16.70 5 2
## 4 15.8 8 351.0 264 4.22 3.170 14.50 5 4
## 5 19.7 6 145.0 175 3.62 2.770 15.50 5 6
## 6 15.0 8 301.0 335 3.54 3.570 14.60 5 84 laply/ ldply/ llply
Split list, apply function, and return results in an array.
laply(baseball, is.factor)## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [12] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSEldply(baseball, is.factor)## .id V1
## 1 id FALSE
## 2 year FALSE
## 3 stint FALSE
## 4 team FALSE
## 5 lg FALSE
## 6 g FALSE
## 7 ab FALSE
## 8 r FALSE
## 9 h FALSE
## 10 X2b FALSE
## 11 X3b FALSE
## 12 hr FALSE
## 13 rbi FALSE
## 14 sb FALSE
## 15 cs FALSE
## 16 bb FALSE
## 17 so FALSE
## 18 ibb FALSE
## 19 hbp FALSE
## 20 sh FALSE
## 21 sf FALSE
## 22 gidp FALSEcolwise(is.factor)(baseball)## id year stint team lg g ab r h X2b X3b hr
## 1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## rbi sb cs bb so ibb hbp sh sf gidp
## 1 FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSElaply(seq_len(10), identity)## [1] 1 2 3 4 5 6 7 8 9 10laply(seq_len(10), rep, times = 4)## 1 2 3 4
## [1,] 1 1 1 1
## [2,] 2 2 2 2
## [3,] 3 3 3 3
## [4,] 4 4 4 4
## [5,] 5 5 5 5
## [6,] 6 6 6 6
## [7,] 7 7 7 7
## [8,] 8 8 8 8
## [9,] 9 9 9 9
## [10,] 10 10 10 10laply(seq_len(10), matrix, nrow = 2, ncol = 2)## , , 1
##
## 1 2
## [1,] 1 1
## [2,] 2 2
## [3,] 3 3
## [4,] 4 4
## [5,] 5 5
## [6,] 6 6
## [7,] 7 7
## [8,] 8 8
## [9,] 9 9
## [10,] 10 10
##
## , , 2
##
## 1 2
## [1,] 1 1
## [2,] 2 2
## [3,] 3 3
## [4,] 4 4
## [5,] 5 5
## [6,] 6 6
## [7,] 7 7
## [8,] 8 8
## [9,] 9 9
## [10,] 10 10#
llply(mtcars, round)## $mpg
## [1] 21 21 23 21 19 18 14 24 23 19 18 16 17 15 10 10 15 32 30 34 22 16 15
## [24] 13 19 27 26 30 16 20 15 21
##
## $cyl
## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
##
## $disp
## [1] 160 160 108 258 360 225 360 147 141 168 168 276 276 276 472 460 440
## [18] 79 76 71 120 318 304 350 400 79 120 95 351 145 301 121
##
## $hp
## [1] 110 110 93 110 175 105 245 62 95 123 123 180 180 180 205 215 230
## [18] 66 52 65 97 150 150 245 175 66 91 113 264 175 335 109
##
## $drat
## [1] 4 4 4 3 3 3 3 4 4 4 4 3 3 3 3 3 3 4 5 4 4 3 3 4 3 4 4 4 4 4 4 4
##
## $wt
## [1] 3 3 2 3 3 3 4 3 3 3 3 4 4 4 5 5 5 2 2 2 2 4 3 4 4 2 2 2 3 3 4 3
##
## $qsec
## [1] 16 17 19 19 17 20 16 20 23 18 19 17 18 18 18 18 17 19 19 20 20 17 17
## [24] 15 17 19 17 17 14 16 15 19
##
## $vs
## [1] 0 0 1 1 0 1 0 1 1 1 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 0 0 0 1
##
## $am
## [1] 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1
##
## $gear
## [1] 4 4 4 3 3 3 3 4 4 4 4 3 3 3 3 3 3 4 4 4 3 3 3 3 3 4 5 5 5 5 5 4
##
## $carb
## [1] 4 4 1 1 2 1 4 2 2 4 4 3 3 3 4 4 4 1 2 1 1 2 2 4 2 1 2 2 4 6 8 2llply(llply(mtcars, round), table)## $mpg
##
## 10 13 14 15 16 17 18 19 20 21 22 23 24 26 27 30 32 34
## 2 1 1 4 3 1 2 3 1 4 1 2 1 1 1 2 1 1
##
## $cyl
##
## 4 6 8
## 11 7 14
##
## $disp
##
## 71 76 79 95 108 120 121 141 145 147 160 168 225 258 276 301 304 318
## 1 1 2 1 1 2 1 1 1 1 2 2 1 1 3 1 1 1
## 350 351 360 400 440 460 472
## 1 1 2 1 1 1 1
##
## $hp
##
## 52 62 65 66 91 93 95 97 105 109 110 113 123 150 175 180 205 215
## 1 1 1 2 1 1 1 1 1 1 3 1 2 2 3 3 1 1
## 230 245 264 335
## 1 2 1 1
##
## $drat
##
## 3 4 5
## 13 18 1
##
## $wt
##
## 2 3 4 5
## 8 13 8 3
##
## $qsec
##
## 14 15 16 17 18 19 20 23
## 1 2 3 9 5 7 4 1
##
## $vs
##
## 0 1
## 18 14
##
## $am
##
## 0 1
## 19 13
##
## $gear
##
## 3 4 5
## 15 12 5
##
## $carb
##
## 1 2 3 4 6 8
## 7 10 3 10 1 1x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
llply(x, mean)## $a
## [1] 5.5
##
## $beta
## [1] 4.535125
##
## $logic
## [1] 0.5llply(x, quantile, probs = 1:3/4)## $a
## 25% 50% 75%
## 3.25 5.50 7.75
##
## $beta
## 25% 50% 75%
## 0.2516074 1.0000000 5.0536690
##
## $logic
## 25% 50% 75%
## 0.0 0.5 1.05 maply/ mdply/ mlply
Call function with arguments in array or data frame, returning an array.
maply(cbind(mean = 1:5, sd = 1:5), rnorm, n = 2)## , , = 1
##
## sd
## mean 1 2 3 4 5
## 1 1.801657 NA NA NA NA
## 2 NA 1.106095 NA NA NA
## 3 NA NA 0.8217647 NA NA
## 4 NA NA NA -2.821501 NA
## 5 NA NA NA NA 9.590347
##
## , , = 2
##
## sd
## mean 1 2 3 4 5
## 1 -1.030519 NA NA NA NA
## 2 NA 0.1580219 NA NA NA
## 3 NA NA 5.815589 NA NA
## 4 NA NA NA 6.255045 NA
## 5 NA NA NA NA 6.517154maply(expand.grid(mean = 1:5, sd = 1:5), rnorm, n = 2)## , , = 1
##
## sd
## mean 1 2 3 4 5
## 1 1.769694 2.504520 4.549259 1.4664670 3.450159
## 2 1.980856 1.460088 2.646320 0.8999684 6.258953
## 3 4.585556 6.166523 5.006672 -3.8949086 6.607827
## 4 4.880003 6.970657 3.990407 7.7987213 5.337034
## 5 7.484481 5.097291 10.876730 8.8536157 -4.297272
##
## , , = 2
##
## sd
## mean 1 2 3 4 5
## 1 0.1975609 0.9011166 2.1824404 4.822353 5.716088
## 2 2.1209043 2.7668559 1.1869081 -0.226855 3.482352
## 3 3.8654387 6.8412029 4.8279667 -5.854408 9.292712
## 4 2.7303377 4.0600362 0.6514371 -3.852541 11.427749
## 5 4.2586197 5.1160319 6.9453713 6.661454 8.823536maply(cbind(1:5, 1:5), rnorm, n = 2)## , , = 1
##
##
## 1 2 3 4 5
## 1 0.8652638 NA NA NA NA
## 2 NA 4.749966 NA NA NA
## 3 NA NA 6.663847 NA NA
## 4 NA NA NA -1.09592 NA
## 5 NA NA NA NA 2.808144
##
## , , = 2
##
##
## 1 2 3 4 5
## 1 2.066592 NA NA NA NA
## 2 NA 0.5606877 NA NA NA
## 3 NA NA 10.46654 NA NA
## 4 NA NA NA 5.488294 NA
## 5 NA NA NA NA 7.01038#
mdply(cbind(mean = 1:5, sd = 1:5), rnorm, n = 5)## mean sd V1 V2 V3 V4 V5
## 1 1 1 2.0787665 2.223941 0.4480055 -0.58103212 -0.1337331
## 2 2 2 2.5410636 4.501332 4.5618587 -0.07465344 3.2049112
## 3 3 3 6.7018207 -3.923504 2.7031612 7.52608293 -2.1594058
## 4 4 4 4.9818659 7.629789 9.5450085 -1.41085091 3.8229480
## 5 5 5 -0.3018354 13.875395 5.7283652 5.88079705 4.2506527mdply(expand.grid(mean = 1:5, sd = 1:5), rnorm, n = 2)## mean sd V1 V2
## 1 1 1 0.5961004 1.3791960
## 2 2 1 1.6291092 1.1251712
## 3 3 1 3.0887375 2.7994661
## 4 4 1 5.0459975 1.6178327
## 5 5 1 5.1887329 5.2133212
## 6 1 2 7.7679693 1.3047763
## 7 2 2 2.6214345 0.1847116
## 8 3 2 2.2126320 2.9372685
## 9 4 2 3.7124170 0.4576352
## 10 5 2 2.9408175 3.3447097
## 11 1 3 2.1436248 0.7998921
## 12 2 3 1.8270963 6.0001164
## 13 3 3 1.9811834 3.9177688
## 14 4 3 3.7146122 6.9759337
## 15 5 3 6.4166485 5.5713630
## 16 1 4 2.4016234 -1.5215914
## 17 2 4 3.7574388 -1.3499098
## 18 3 4 1.5066352 5.2455257
## 19 4 4 8.2638396 0.4191990
## 20 5 4 2.6317600 9.4836330
## 21 1 5 1.0570083 -2.6440292
## 22 2 5 0.1118640 2.7049722
## 23 3 5 6.5042379 5.8349988
## 24 4 5 5.6982451 9.1249979
## 25 5 5 12.2881738 5.0561882mdply(cbind(mean = 1:5, sd = 1:5), as.data.frame(rnorm), n = 5)## mean sd value
## 1 1 1 -0.5532740
## 2 1 1 1.7532357
## 3 1 1 0.0986697
## 4 1 1 0.4944914
## 5 1 1 1.0396215
## 6 2 2 5.0723042
## 7 2 2 0.5392697
## 8 2 2 1.6056064
## 9 2 2 2.5414284
## 10 2 2 3.0733797
## 11 3 3 4.0729889
## 12 3 3 9.1024527
## 13 3 3 8.0094705
## 14 3 3 6.8332345
## 15 3 3 0.2661260
## 16 4 4 6.7809214
## 17 4 4 7.9940996
## 18 4 4 6.3757652
## 19 4 4 4.0488428
## 20 4 4 4.3720060
## 21 5 5 5.8582439
## 22 5 5 11.2575084
## 23 5 5 0.3501260
## 24 5 5 3.6368174
## 25 5 5 9.8025286#
mlply(cbind(1:4, 4:1), rep)## $`1`
## [1] 1 1 1 1
##
## $`2`
## [1] 2 2 2
##
## $`3`
## [1] 3 3
##
## $`4`
## [1] 4
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
##
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 1mlply(cbind(1:4, times = 4:1), rep)## $`1`
## [1] 1 1 1 1
##
## $`2`
## [1] 2 2 2
##
## $`3`
## [1] 3 3
##
## $`4`
## [1] 4
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
## times
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 1mlply(cbind(1:4, 4:1), seq)## $`1`
## [1] 1 2 3 4
##
## $`2`
## [1] 2 3
##
## $`3`
## [1] 3 2
##
## $`4`
## [1] 4 3 2 1
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
##
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 1mlply(cbind(1:4, length = 4:1), seq)## $`1`
## [1] 1 2 3 4
##
## $`2`
## [1] 2 3 4
##
## $`3`
## [1] 3 4
##
## $`4`
## [1] 4
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
## length
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 1mlply(cbind(1:4, by = 4:1), seq, to = 20)## $`1`
## [1] 1 5 9 13 17
##
## $`2`
## [1] 2 5 8 11 14 17 20
##
## $`3`
## [1] 3 5 7 9 11 13 15 17 19
##
## $`4`
## [1] 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
##
## attr(,"split_type")
## [1] "array"
## attr(,"split_labels")
## by
## 1 1 4
## 2 2 3
## 3 3 2
## 4 4 16 raply/ rdply/ rlply
Replicate expression and return results in a array/ data.frame/ list
raply(10, mean(runif(100)))## [1] 0.4910119 0.5024170 0.5003596 0.4809902 0.4828145 0.5365963 0.5106904
## [8] 0.5027685 0.5109807 0.5196246raply(10, each(mean, var)(runif(100)))## mean var
## [1,] 0.5434708 0.08560793
## [2,] 0.4682580 0.07898800
## [3,] 0.5042066 0.08370707
## [4,] 0.4871877 0.09328363
## [5,] 0.5333053 0.08355126
## [6,] 0.5303828 0.08755262
## [7,] 0.5022448 0.09076764
## [8,] 0.5391451 0.07751627
## [9,] 0.5060296 0.08053948
## [10,] 0.5427813 0.10018072hist(raply(1000, mean(rexp(1000))))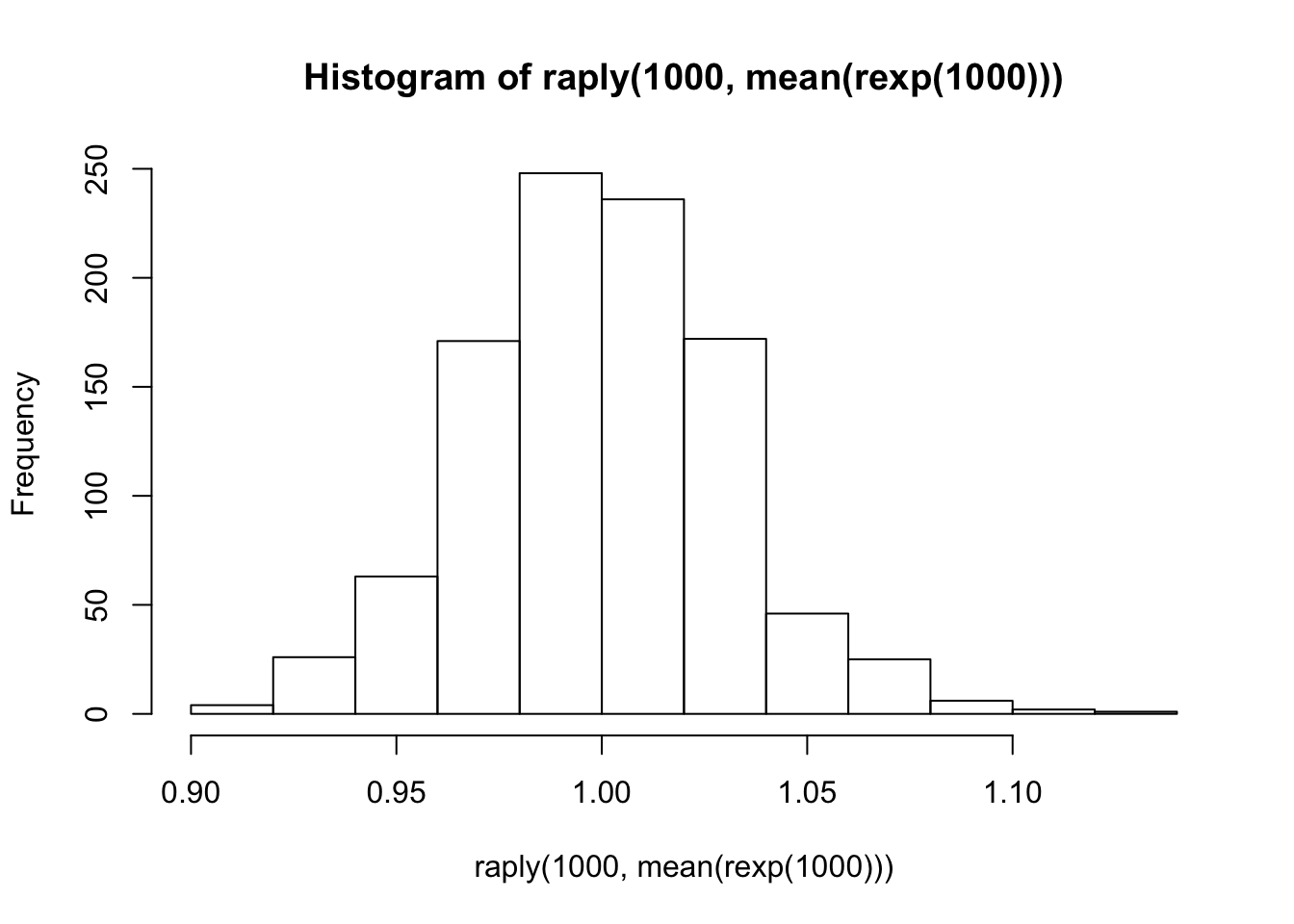
#
rdply(20, each(mean, var)(runif(100)))## .n mean var
## 1 1 0.5353184 0.07202726
## 2 2 0.4685266 0.07709420
## 3 3 0.5146181 0.07449306
## 4 4 0.5296048 0.08182465
## 5 5 0.4847191 0.09275419
## 6 6 0.5406801 0.08494226
## 7 7 0.5007430 0.08600186
## 8 8 0.4948883 0.07834916
## 9 9 0.4789544 0.09872664
## 10 10 0.5260734 0.08358004
## 11 11 0.5411781 0.08026287
## 12 12 0.4757993 0.07788696
## 13 13 0.5261861 0.08718621
## 14 14 0.4808975 0.08441186
## 15 15 0.5059638 0.08007830
## 16 16 0.5143309 0.09769331
## 17 17 0.4989572 0.08590434
## 18 18 0.4380903 0.08102582
## 19 19 0.4771784 0.09595031
## 20 20 0.4556680 0.06813685#
mods <- rlply(100, lm(y ~ x, data=data.frame(x=rnorm(100), y=rnorm(100))))
hist(laply(mods, function(x) summary(x)$r.squared))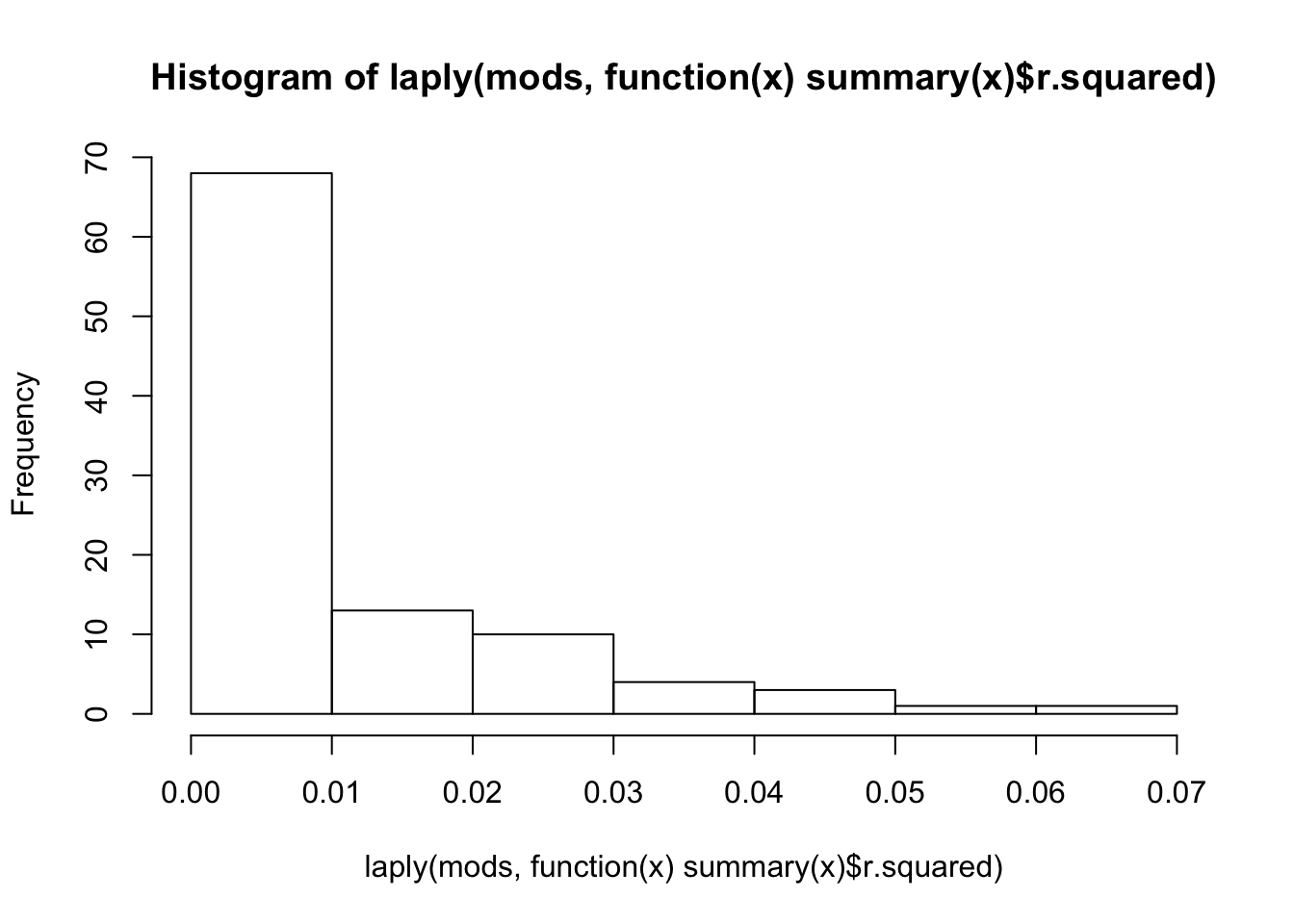
7 arrange
Order a data frame by its colums.
arrange(mtcars, cyl, disp) #same as mtcars[with(mtcars, order(cyl, disp)), ]## mpg cyl disp hp drat wt qsec vs am gear carb
## 1 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## 2 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## 3 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## 4 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## 5 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## 6 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 7 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## 8 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## 9 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
## 10 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 11 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 12 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## 13 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 14 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 15 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## 16 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## 17 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 18 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 19 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
## 20 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
## 21 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
## 22 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
## 23 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
## 24 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
## 25 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
## 26 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## 27 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 28 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## 29 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
## 30 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
## 31 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
## 32 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 48 decent
Transform a vector into a format that will be sorted in descending order
desc(1:10)## [1] -1 -2 -3 -4 -5 -6 -7 -8 -9 -10desc(factor(letters))## [1] -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 -11 -12 -13 -14 -15 -16 -17
## [18] -18 -19 -20 -21 -22 -23 -24 -25 -269 colwise
Turn a function that operates on a vector into a function that operates column-wise on a data.frame.
nmissing <- function(x) sum(is.na(x))
# Apply to every column in a data frame
colwise(nmissing)(baseball)## id year stint team lg g ab r h X2b X3b hr rbi sb cs bb so ibb hbp
## 1 0 0 0 0 0 0 0 0 0 0 0 0 12 250 4525 0 1305 7528 377
## sh sf gidp
## 1 960 7390 527210 count
Equivalent to as.data.frame(table(x)), but does not include combinations with zero counts.
count(mtcars,"cyl")## cyl freq
## 1 4 11
## 2 6 7
## 3 8 14count(mtcars,"cyl","gear")## cyl freq
## 1 4 45
## 2 6 27
## 3 8 4611 each
Aggregate multiple functions into a single function
12 failwith
Modify a function so that it returns a default value when there is an error.
f <- function(x) if (x == 1) stop("Error!") else 1
f(1)
f(2)
safef <- failwith(NULL, f)
safef(1)
safef(2)13 match_df
Extract matching rows of a data frame
longterm <- subset(count(baseball, "id"), freq > 25)
bb_longterm <- match_df(baseball, longterm)## Matching on: iddim(baseball)## [1] 21699 22dim(longterm)## [1] 14 2dim(bb_longterm)## [1] 383 2214 mutate
Mutate a data frame by adding new or replacing existing columns.
head(airquality)## Ozone Solar.R Wind Temp Month Day
## 1 41 190 7.4 67 5 1
## 2 36 118 8.0 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6head(mutate(airquality, Temp = (Temp - 32) / 1.8, ozt = Ozone / Temp))## Ozone Solar.R Wind Temp Month Day ozt
## 1 41 190 7.4 19.44444 5 1 2.1085714
## 2 36 118 8.0 22.22222 5 2 1.6200000
## 3 12 149 12.6 23.33333 5 3 0.5142857
## 4 18 313 11.5 16.66667 5 4 1.0800000
## 5 NA NA 14.3 13.33333 5 5 NA
## 6 28 NA 14.9 18.88889 5 6 1.482352915 join
Join two data frames together.
16 rbind.fill/ rbind.fill.matrix
Combine data.frames by row, filling in missing columns Bind matrices by row, and fill missing columns with NA
rbind.fill(mtcars[c("mpg", "wt")], mtcars[c("wt", "cyl")])## mpg wt cyl
## 1 21.0 2.620 NA
## 2 21.0 2.875 NA
## 3 22.8 2.320 NA
## 4 21.4 3.215 NA
## 5 18.7 3.440 NA
## 6 18.1 3.460 NA
## 7 14.3 3.570 NA
## 8 24.4 3.190 NA
## 9 22.8 3.150 NA
## 10 19.2 3.440 NA
## 11 17.8 3.440 NA
## 12 16.4 4.070 NA
## 13 17.3 3.730 NA
## 14 15.2 3.780 NA
## 15 10.4 5.250 NA
## 16 10.4 5.424 NA
## 17 14.7 5.345 NA
## 18 32.4 2.200 NA
## 19 30.4 1.615 NA
## 20 33.9 1.835 NA
## 21 21.5 2.465 NA
## 22 15.5 3.520 NA
## 23 15.2 3.435 NA
## 24 13.3 3.840 NA
## 25 19.2 3.845 NA
## 26 27.3 1.935 NA
## 27 26.0 2.140 NA
## 28 30.4 1.513 NA
## 29 15.8 3.170 NA
## 30 19.7 2.770 NA
## 31 15.0 3.570 NA
## 32 21.4 2.780 NA
## 33 NA 2.620 6
## 34 NA 2.875 6
## 35 NA 2.320 4
## 36 NA 3.215 6
## 37 NA 3.440 8
## 38 NA 3.460 6
## 39 NA 3.570 8
## 40 NA 3.190 4
## 41 NA 3.150 4
## 42 NA 3.440 6
## 43 NA 3.440 6
## 44 NA 4.070 8
## 45 NA 3.730 8
## 46 NA 3.780 8
## 47 NA 5.250 8
## 48 NA 5.424 8
## 49 NA 5.345 8
## 50 NA 2.200 4
## 51 NA 1.615 4
## 52 NA 1.835 4
## 53 NA 2.465 4
## 54 NA 3.520 8
## 55 NA 3.435 8
## 56 NA 3.840 8
## 57 NA 3.845 8
## 58 NA 1.935 4
## 59 NA 2.140 4
## 60 NA 1.513 4
## 61 NA 3.170 8
## 62 NA 2.770 6
## 63 NA 3.570 8
## 64 NA 2.780 4A <- matrix (1:4, 2)
B <- matrix (6:11, 2)
A## [,1] [,2]
## [1,] 1 3
## [2,] 2 4B## [,1] [,2] [,3]
## [1,] 6 8 10
## [2,] 7 9 11rbind.fill.matrix (A, B)## 1 2 3
## [1,] 1 3 NA
## [2,] 2 4 NA
## [3,] 6 8 10
## [4,] 7 9 1117 rename
Modify names by name, not position
rename(mtcars, c("disp" = "displ"))## mpg cyl displ hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 218 summarise
Summarise works in an analagous way to transform, except instead of adding columns to an existing data frame, it creates a new one. This is particularly useful in conjunction with ddply as it makes it easy to perform group-wise summaries.
summarise(baseball, duration = max(year) - min(year),
nteams = length(unique(team)))## duration nteams
## 1 136 132head(ddply(baseball, "id", summarise, duration = max(year) - min(year), nteams = length(unique(team))) )## id duration nteams
## 1 aaronha01 22 3
## 2 abernte02 17 7
## 3 adairje01 12 4
## 4 adamsba01 20 2
## 5 adamsbo03 13 4
## 6 adcocjo01 16 519 vaggregate
n <- 17; fac <- factor(rep(1:3, length = n), levels = 1:5)
table(fac)## fac
## 1 2 3 4 5
## 6 6 5 0 0vaggregate(1:n, fac, sum)## [1] 51 57 45 0 0vaggregate(1:n, fac, sum, .default = NA_integer_)## [1] 51 57 45 NA NAvaggregate(1:n, fac, range)## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 2 3 Inf Inf
## [2,] 16 17 15 -Inf -Infvaggregate(1:n, fac, range, .default = c(NA, NA) + 0)## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 2 3 NA NA
## [2,] 16 17 15 NA NAvaggregate(1:n, fac, quantile)## [,1] [,2] [,3] [,4] [,5]
## 0% 1.00 2.00 3 NA NA
## 25% 4.75 5.75 6 NA NA
## 50% 8.50 9.50 9 NA NA
## 75% 12.25 13.25 12 NA NA
## 100% 16.00 17.00 15 NA NA